

Analisis Regresi Linear Sederhana
Regresi Linear Sederhana adalah Metode Statistik yang berfungsi untuk menguji sejauh mana hubungan sebab akibat antara Variabel Faktor Penyebab (X) terhadap Variabel Akibatnya. Faktor Penyebab pada umumnya dilambangkan dengan X atau disebut juga dengan Predictor sedangkan Variabel Akibat dilambangkan dengan Y atau disebut juga dengan Response. Regresi Linear Sederhana atau sering disingkat dengan SLR (Simple Linear Regression) juga merupakan salah satu Metode Statistik yang dipergunakan dalam produksi untuk melakukan peramalan ataupun prediksi tentang karakteristik kualitas maupun Kuantitas.
Contoh Penggunaan Analisis Regresi Linear Sederhana dalam Produksi antara lain :
- Hubungan antara Lamanya Kerusakan Mesin dengan Kualitas Produk yang dihasilkan
- Hubungan Jumlah Pekerja dengan Output yang diproduksi
- Hubungan antara suhu ruangan dengan Cacat Produksi yang dihasilkan.
Model Persamaan Regresi Linear Sederhana adalah seperti berikut ini :
Dimana :
Y = Variabel Response atau Variabel Akibat (Dependent)
X = Variabel Predictor atau Variabel Faktor Penyebab (Independent)
a = konstanta
b = koefisien regresi (kemiringan); besaran Response yang ditimbulkan oleh Predictor.
Nilai-nilai a dan b dapat dihitung dengan menggunakan Rumus dibawah ini :
a = (Σy) (Σx²) – (Σx) (Σxy)
. n(Σx²) – (Σx)²
b = n(Σxy) – (Σx) (Σy)
. n(Σx²) – (Σx)²
Berikut ini adalah Langkah-langkah dalam melakukan Analisis Regresi Linear Sederhana :
- Tentukan Tujuan dari melakukan Analisis Regresi Linear Sederhana
- Identifikasikan Variabel Faktor Penyebab (Predictor) dan Variabel Akibat (Response)
- Lakukan Pengumpulan Data
- Hitung X², Y², XY dan total dari masing-masingnya
- Hitung a dan b berdasarkan rumus diatas.
- Buatkan Model Persamaan Regresi Linear Sederhana.
- Lakukan Prediksi atau Peramalan terhadap Variabel Faktor Penyebab atau Variabel Akibat.
Contoh Kasus Analisis Regresi Linear Sederhana
Seorang Engineer ingin mempelajari Hubungan antara Suhu Ruangan dengan Jumlah Cacat yang diakibatkannya, sehingga dapat memprediksi atau meramalkan jumlah cacat produksi jika suhu ruangan tersebut tidak terkendali. Engineer tersebut kemudian mengambil data selama 30 hari terhadap rata-rata (mean) suhu ruangan dan Jumlah Cacat Produksi.
Penyelesaian
Penyelesaiannya mengikuti Langkah-langkah dalam Analisis Regresi Linear Sederhana adalah sebagai berikut :
Langkah 1 : Penentuan Tujuan
Tujuan : Memprediksi Jumlah Cacat Produksi jika suhu ruangan tidak terkendali
Langkah 2 : Identifikasikan Variabel Penyebab dan Akibat
Varibel Faktor Penyebab (X) : Suhu Ruangan,
Variabel Akibat (Y) : Jumlah Cacat Produksi
Langkah 3 : Pengumpulan Data
Berikut ini adalah data yang berhasil dikumpulkan selama 30 hari (berbentuk tabel) :
Tanggal
|
Rata-rata Suhu Ruangan
|
Jumlah Cacat
|
1
|
24
|
10
|
2
|
22
|
5
|
3
|
21
|
6
|
4
|
20
|
3
|
5
|
22
|
6
|
6
|
19
|
4
|
7
|
20
|
5
|
8
|
23
|
9
|
9
|
24
|
11
|
10
|
25
|
13
|
11
|
21
|
7
|
12
|
20
|
4
|
13
|
20
|
6
|
14
|
19
|
3
|
15
|
25
|
12
|
16
|
27
|
13
|
17
|
28
|
16
|
18
|
25
|
12
|
19
|
26
|
14
|
20
|
24
|
12
|
21
|
27
|
16
|
22
|
23
|
9
|
23
|
24
|
13
|
24
|
23
|
11
|
25
|
22
|
7
|
26
|
21
|
5
|
27
|
26
|
12
|
28
|
25
|
11
|
29
|
26
|
13
|
30
|
27
|
14
|
Langkah 4 : Hitung X², Y², XY dan total dari masing-masingnya
Berikut ini adalah tabel yang telah dilakukan perhitungan X², Y², XY dan totalnya :
Tanggal
|
Rata-rata Suhu Ruangan (X)
|
Jumlah Cacat (Y)
|
X2
|
Y2
|
XY
|
1
|
24
|
10
|
576
|
100
|
240
|
2
|
22
|
5
|
484
|
25
|
110
|
3
|
21
|
6
|
441
|
36
|
126
|
4
|
20
|
3
|
400
|
9
|
60
|
5
|
22
|
6
|
484
|
36
|
132
|
6
|
19
|
4
|
361
|
16
|
76
|
7
|
20
|
5
|
400
|
25
|
100
|
8
|
23
|
9
|
529
|
81
|
207
|
9
|
24
|
11
|
576
|
121
|
264
|
10
|
25
|
13
|
625
|
169
|
325
|
11
|
21
|
7
|
441
|
49
|
147
|
12
|
20
|
4
|
400
|
16
|
80
|
13
|
20
|
6
|
400
|
36
|
120
|
14
|
19
|
3
|
361
|
9
|
57
|
15
|
25
|
12
|
625
|
144
|
300
|
16
|
27
|
13
|
729
|
169
|
351
|
17
|
28
|
16
|
784
|
256
|
448
|
18
|
25
|
12
|
625
|
144
|
300
|
19
|
26
|
14
|
676
|
196
|
364
|
20
|
24
|
12
|
576
|
144
|
288
|
21
|
27
|
16
|
729
|
256
|
432
|
22
|
23
|
9
|
529
|
81
|
207
|
23
|
24
|
13
|
576
|
169
|
312
|
24
|
23
|
11
|
529
|
121
|
253
|
25
|
22
|
7
|
484
|
49
|
154
|
26
|
21
|
5
|
441
|
25
|
105
|
27
|
26
|
12
|
676
|
144
|
312
|
28
|
25
|
11
|
625
|
121
|
275
|
29
|
26
|
13
|
676
|
169
|
338
|
30
|
27
|
14
|
729
|
196
|
378
|
Total (Σ)
|
699
|
282
|
16487
|
3112
|
6861
|
Langkah 5 : Hitung a dan b berdasarkan rumus Regresi Linear Sederhana
Menghitung Konstanta (a) :
a = (Σy) (Σx²) – (Σx) (Σxy)
. n(Σx²) – (Σx)²
a = (282) (16.487) – (699) (6.861)
30 (16.487) – (699)²
a = -24,38
Menghitung Koefisien Regresi (b)
b = n(Σxy) – (Σx) (Σy)
. n(Σx²) – (Σx)²
b = 30 (6.861) – (699) (282)
. 30 (16.487) – (699)²
b = 1,45
Langkah 6 : Buat Model Persamaan Regresi
Y = a + bX
Y = -24,38 + 1,45X
Langkah 7 : Lakukan Prediksi atau Peramalan terhadap Variabel Faktor Penyebab atau Variabel Akibat
I. Prediksikan Jumlah Cacat Produksi jika suhu dalam keadaan tinggi (Variabel X), contohnya : 30°C
Y = -24,38 + 1,45 (30)
Y = 19,12
Jadi Jika Suhu ruangan mencapai 30°C, maka akan diprediksikan akan terdapat 19,12 unit cacat yang dihasilkan oleh produksi.
II. Jika Cacat Produksi (Variabel Y) yang ditargetkan hanya boleh 4 unit, maka berapakah suhu ruangan yang diperlukan untuk mencapai target tersebut ?
4 = -24,38 + 1,45X
1,45X = 4 + 24,38
X = 28,38 / 1,45
X = 19,57
Jadi Prediksi Suhu Ruangan yang paling sesuai untuk mencapai target Cacat Produksi adalah sekitar 19,57°C
Analisis Regresi Linear Berganda
Analisis regresi merupakan salah satu teknik analisis data dalam statistika yang seringkali digunakan untuk mengkaji hubungan antara beberapa variabel dan meramal suatu variabel (Kutner, Nachtsheim dan Neter, 2004).
Dalam mengkaji hubungan antara beberapa variabel menggunakan analisis regresi, terlebih dahulu peneliti menentukan satu variabel yang disebut dengan variabel tidak bebas dan satu atau lebih variabel bebas. Jika ingin dikaji hubungan atau pengaruh satu variabel bebas terhadap variabel tak bebas, maka model regresi yang digunakan model regresi linear sederhana. Kemudian jika ingin dikaji hubungan atau pengaruh dua atau lebih variabel bebas terhadap variabel tak bebas, maka model regresi yang digunakan adalah model regresi linear berganda (multiple linear regression model). Kemudian untuk mendapatkan model regresi linear sederhana maupun model regresi linear berganda dapat diperoleh dengan melakukan estimasi terhadap parameter-parameternya menggunakan metode tertentu. Adapun metode yang dapat digunakan untuk mengestimasi parameter model regresi linier sederhana maupun model regresi linier berganda adalah dengan metode kuadrat terkecil (ordinary least square/OLS) dan metode kemungkinan maksimum (maximum likelihood estimation/MLE) (Kutner et.al, 2004)
Bentuk umum model regresi linear berganda dengan p variabel bebas seperti pada persamaan berikut.

Tujuan Analisis
1. Membuat estimasi rata-rata dan nilai variabel tergantung dengan didasarkan pada nilai variabel bebas.
2. Membangun hipotesis karakteristik dependensi.
3. Untuk meramalkan nilai rata-rata ariable bebas dengan didasarkan pada nilai ariable bebas di luar jangkauan sampel.

Estimasi Parameter Model Regresi Linear Berganda
Estimasi parameter ini bertujuan untuk mendapatkan model regresi linear berganda yang akan digunakan dalam analisis. Pada penelitian ini, metode yang digunakan untuk mengestimasi parameter model regresi linear berganda adalah metode kuadrat terkecil atau sering juga disebut metode ordinary least square (OLS). Metode OLS ini bertujuan meminimumkan jumlah kuadrat error. Berdasarkan persamaan (3.1) dapat diperoleh penaksir (estimator) OLS untuk β adalah sebagai berikut (Kutner, et.al, 2004).

Penaksir OLS pada persamaan (3.2) merupakan penaksir yang tidak bisa, linear, dan terbaik (Best Linear Unbiased Estimator/BLUE) (Sembiring, 2003, Gujarati, 2003, Greene, 2003, dam Widarjono, 2007).
Kriteria Pemilihan Model
Pengujian signifikansi koefisien regresi bermanfaat untuk melihat validitas (kesahihan) model yang terbentuk. Kadangkala ada beberapa model yang cocok dengan data, dalam arti valid secara statistik. Dalam kasus seperti ini, untuk tujuan perbandingan atau pemilihan model, uji signifikansi koefisien saja belumlah cukup. Diperlukan beberapa ukuran lain yang berfungsi sebagai patokan (benchmark) dalam membandingkan beberapa model yang valid tersebut.
1. Koefisien determinasi (Rsquared)
Koefisien determinasi pada intinya mengukur seberapa jauh kemampuan model dalam menerangkan variasi variabel independen. Nilai kemampuan model dalam menerangkan variasi variabel dependen. Nilai Rsquared yang kecil berarti kemampuan variabel-variabel independen dalam menjelaskan variasi variabel dependen amat terbatas. Nilai yang mendekati satu berarti variabel-variabel independen memberikan hampir semua informasi yang dibutuhkan untuk memprediksi variasi variabel dependen. Secara umum koefisien determinasi untuk data silang (crossection) relatif rendah karena adanya variasi yang besar antara masing-masing pengamatan, sedangkan untuk data runtut waktu (time series) biasanya mempunyai nilai koefisien determinasi yang tinggi.
Kadangkala peneliti ingin memaksimumkan nilai Rsquared sehingga mencari model yang menghasilkan nilai Rsquared tinggi. Hal ini jika dilakukan berbahaya karena tujuan analisis regresi bukan semata ingin mendapatkan nilai Rsquared yang tinggi, tetapi mencari nilai estimasi koefisien regresi dan menarik inferensi statistik. Dalam kenyataan empiris biasa ditemukan regresi dengan nilai Rsquared yang tinggi, tetapi nilai koefisien regresi tidak ada yang signifikan atau memiliki tanda koefisien yang berlawanan dari yang diharapkan secara teori. Jadi sebaiknya peneliti lebih melihat logika atau penjelasan teoritis pengaruh variabel explanatory terhadap variabel dependen. Jika dalam proses mendapatkan Rsquared tinggi adalah baik, tetapi jika nilai Rsquared rendah tidak berarti model regresi jelek.
Suatu hal yang perlu dicatat adalah masalah regresi lancung (spurious regression). Insukindro (1998) menekankan bahwa koefisien determinasi hanyalah salah satu dan bukan satu-satunya kriteria memilih model yang baik. Alasannya bila suatu estimasi regresi linear menghasilkan koefisien determinasi yang tinggi, tetapi jika tidak konsisten dengan teori ekonomika yang dipilih oleh peneliti, atau tidak lolos dari uji asumsi klasik, maka model tersebut bukanlah model penaksir yang baik dan seharusnya tidak dipilih menjadi model empirik.
Kelemahan mendasar penggunaan koefisien determinasi adalah bias terhadap variabel independen yang dimasukkan kedalam model. Setiap tambahan satu variabel independen, maka nilai Rsquared pasti meningkat tidak peduli apakah variabel tersebut berpengaruh secara signifikan terhadap variabel dependen. Oleh karena banyak peneliti menganjurkan untuk menggunakan nilai adjusted Rsquared pada saat mengevaluasi mana model regresi terbaik. Tidak seperti Rsquared, nilai adjusted Rsquared dapat naik atau turun apabila satu variabel independen ditambah dalam model.
Dalam kenyataan nilai adjusted Rsquared dapat bernilai negatif, walaupun yang dikehendaki harus positif. Menurut Gujarati (2003) jika dalam uji empiris didapat nilai adjusted R2 negatif, maka nilai adjusted Rsquared dianggap bernilai nol. Secara matematis jika nilai Rsquared = 1, maka adjusted Rsquared = Rsquared = 1, sedangkan jika nilai Rsquared = 0, maka nilai adjusted Rsquared = (1-k)/(n-k). Jika k > 1, maka adjusted Rsquared akan bernilai negatif.
2. Residual standard error
Residual standard error merupakan ukuran kestabilan prediksi dari model regresi yang bersangkutan. Semakin kecil nilainya, maka model akan semakin baik.

Dengan :
n = banyaknya sampel
k = banyaknya prediktor dalam model termasuk intersep
3. AIC dan BIC
Metode AIC dan BIC adalah metode yang dapat digunakan untuk memilih model regresi terbaik yang ditemukan oleh Akaike dan Schwarz (Grasa, 1989). Kedua metode tersebut didasarkan pada metode maximum likelihood estimation (MLE).
Untuk menghitung nilai AIC dan BIC digunakan rumus sebagai berikut :

Menurut metode AIC dan BIC, model regresi terbaik adalah model regresi yang mempunyai nilai AIC dan BIC terkecil (Widarjono, 2007).
Asumsi Klasik
1. Normalitas Residual
Uji normalitas residual adalah untuk melihat apakah nilai residual terdistribusi normal atau tidak. Model regresi yang baik adalah memiliki nilai residual yang terdistribusi normal. Kalau asumsi ini dilanggar maka uji statistik menjadi tidak valid untuk jumlah sampel kecil. Ada dua cara umendeteksi apakah residual memiliki distribusi normal atau tidak yaitu dengan analisis grafik dan uji statistik.
Analisis grafik
Salah satu cara termudah untuk melihat normalitas adalah melihat histogram yang membandingkan antara data observasi dengan sitribusi yang mendekati distribusi normal. Namun demikian dengan hanya melihat histogram hal ini bisa menyesatkan khususnya untuk jumlah sampel yang kecil. Metode yang lebih handal adalah dengan melihat normal probability plot yang membandingkan distribusi kumulatif dari data sesungguhnya dengan distribusi kumulatif dari distribusi normal. Distribusi normal akan membentuk satu garis lurus diagonal, dan ploting data akan dibandingkan dengan garis diagonal. Jika distribusi data adalah normal, maka garis yang menggambarkan data sesungguhnya akan mengikuti garis diagonalnya.
Pada prinsipnya normalitas dapat dideteksi dengan melihat penyebaran data (titik) pada sumbu diagonal dari grafik atau dengan melihat histogram dari residualnya. Dasar pengambilan keputusan adalah :
· Jika data menyebar di sekitar garis diagonal dan mengikuti arah grasi diagonal atau grafik histogramnya menunjukkan pola distribusi normal, maka model regresi memnuhi asumsi normalitas.
· Jika data menyebar jauh dari garis diagonal dan/atau tidak mengikuti arah garis diagonal atau grafik histogram tidak menunjukkan pola distribus normal, maka model regresi tidak memenuhi asumsi normalitas.
Analisis statistik
Uji normalitas residual dengan grafik dapat menyesatkan kalau tidak hati-hati. Secara visual kelihatan normal, padahal secara statistik bisa sebaliknya. Oleh sebab itu dianjurkan disamping grafik dilengkapi dengan uji statistik.
Uji Jarque-Bera (JB) dapat digunakan untuk uji normalitas sampel besar (asymtotic). Pertama hitung nilai Skewness dan Kurtosis untuk residual, kemudian lakukan uji KB statistik dengan rumus seperti di bawah ini :

Dimana n = besarnya sampel, S = koefisien skewness, K = koefisien kurtosis. Nilai JB statistik mengikuti distribusi chisquare dengan 2 df (degree of freedom). (Imam Ghozali, 2014)
2. Heteroskedastisitas
Asumsi klasik keempat dari Classical linear regression Model adalah nilai residual atau error dalam model regresi memiliki variance yang sama atau disebut homoskedastisitas. Jadi, asumsi homoskedastisitas berarti sama (homo) dan sebaran (scedasticity) memiliki variance yang sama (equal variance) atau secara matematis dapat ditulis sebagai berikut :
Asumsi ini menyatakan bahwa varians dari faktor pengganggu pada model regresi adalah sama untuk semua nili X (atas semua percobaan).
Jika asumsi ini dilanggar, akan terjadi kaus heteroskedastisitas atau varians tidak sama untuk semua nilai X.
Ada beberapa penyebab variance dari (residual) tidak konstan, tetapi bervariasi, antara lain :
· Error-learning Model pembelajaran kesalahan menyatakan bahwa seseorang akan belajar dari pengalaman, sehingga perilaku salah akan semakin kecil sepanjang waktu dan dalam hal ini nilai variance diharapkan semakin menurun. Sebagai contoh, kasus kesalahan mengetik tergantung dari waktu lamanya praktik mengetik. Semakin meningkat jumlah jam praktik mengetik, semakin menurun jumlah kesalahan mengetik begitu juga dengan variance semakin menurun.
· Adanya perbaikan dalam teknik pengumpulan data, maka variance akan semakin menurun. Bank yang memiliki peralatan pengolahan data yang canggih cenderung memiliki kesalahan yang kecil dalam penyampaian laporan kepada nasabahnya dibandingkan pada bank yang peralatan pengolahan datanya kurang canggih.
· Adanya data yang outlier
· Adanya pelanggaran terhadap asumsi klasik kesembilan yaitu model regresi telah dispesifikkan secara benar
Masalah heteroskedastisitas umum terjadi pada data silang (crossectional) daripada data runtut waktu (time series). Pada data silang waktu, biasanya kita berhubungan dengan anggota populasi pada satu waktu tertentu seperti konsumen individual, perusahaan, industri, dan lain-lain. Anggota populasi itu memiliki perbedaan ukuran. Sementara itu pada data runtut waktu variabel cenderung urutan besaran yang sama karena data dikumpulkan pada entitas yang sama selama periode waktu tertentu.
Heteroskedastisitas tidak merusak property dari estimasi ordinary least square (OLS) yaitu tetap tidak bias (unbiased) dan konsisten estimator. Tetapi estimator ini tidak lagi memiliki minimum variance dan tidak lagi efisien. Sehingga tidak lagi memenuhi BLUE (Best Linear Unbiased Estimator).
3. No Multicollinearity
Asumsi ke 10 dari model regresi linear klasik (classical linear regression model) menyatakan tidak ada multikolinearitas yang tinggi atau sempurna antar variabel independen. Uji multikoliearitas bertujuan untuk menguji apakah dalam model regeresi ditemukan adanya korelasi yang tinggi atau sempurna antar variabel independen. Jika antar variabel independen X’s terjadi multikoliearitas sempurna, maka koefesien regresi variabel X tidak dapat ditentukan dan nilai standard error menjadi tak terhingga. Jika multikolinearitas antar variabel X’s tidak sempurna tetapi tinggi, maka koefisien regresi X dapat ditentukan, tetapi tidak memiliki nilai standard error tinggi yang berarti nilai koefisien regresi tidak dapat diestimasi dengan tepat.
Asumsi klasik ke 7 yang menyatakan jumlah observasi harus lebih besar dari variabel independen dan asumsi klasik ke 8 yang menyatakan bahwa variabel independen harus memiliki variabilitas yang cukup tinggi. Kedua asumsi ni melengkapi asumsi multikolinearitas. Jika asumsi klasik terpenuhi, maka estimasi regresi dengan OLS akan BLUE (Best Linear Unbiased Estimator). Jadi dapat disimpulkan meskipun terjadi multikolinearitas tinggi antar variabel independen, OLS estimator tetap BLUE. Pengaruh dari Multikolinearitas hanyalah sulit untuk mendapatkan koefisien dengan standar error yang kecil. Hal ni juga akan terjadi jika jumlah observasi kecil atau sering disebut masalah micronumerosity.
Ada beberapa penyebab multikolinearitas :
· Metode pengumpulan data yang digunakan.
· Adanya constrain pada model atau populasi yang dijadikan sampel.
· Model spesifikasi.
· Overdetermined model, hal ini terjadi ketika model regresi memiliki jumlah variabel independen yang lebih besar dari pada observasi.
Adanya multikolinearitas yang tinggi antar variabel independen menimbulkan beberapa akibat seperti terlihat dibawah ini :
· Walaupun regresi OLS masih BLUE, tetapi estimasi OLS memberikan nilai varian dan kovarian yang tinggi sulit memperoleh nilai estimasi yang tepat.
· Oleh karena akibat no 1, nilai confidence interval cenderung makin lebar sehingga lebih judah untuk tidak menolak hipotesis nol.
· Oleh karena akibat no 1, nilai t satu atau lebih koefisien cenderung tidak signifikan secara statistik.
· Walaupun nilai t ratio satu atau lebih koefisien tidak signifikan, nilai R2 yang mengukur overall goodness-of-fit sangat tinggi.
· Nilai estimator OLS dan standard errornya sensitif terhadap perubahan kecil dalam data.
Adanya multikolinearitas atau korelasi yang tinggi antar variabel independen dapat dideteksi dengan beberapa cara di bawah ini :
· Nilai Rsquared tinggi, tetapi hanya sedikit nilai t ratio yang signifikan. Jika nilai Rsquared tinggi di atas 0,80 maka uji F pada sebagian besar kasus akan menolak hipotesis yang menyatakan bahwa koefisien slope parsial simultan sama dengan nol, tetapi uji t individual menunjukkan sangat sedikit koefisien slope parsial yang secara statistik berbeda dengan nol.
· Adanya pair-wise correlation yang tinggi antar variabel independen. Jika pair-wise atau zero order correlation antar dua variabel independen tinggi, katakan 0,80 maka multikolinearitas merupakan masalah serius. Hal ini dapat dideteksi dengan melihat matriks korelasi antar-variabel independen.
· Melihat korelasi parsial. Pada regresi variabel X2, X3, dan X4 terhadap Y, jika nilai R21.234 sangat tinggi, tetapi r22.3, r22.4, dan r23.4 relatif rendah nilainya, maka dapat disimpulkan bahwa variabel X2, X3, dan X4 saling berkorelasi tinggi dan salah satu dari variabel ini superfluous.

· Auxilary regression. Multikolinearitas timbul karena satu atau lebih variabel independen berkorelasi secara linear dengan variabel independen lainnya. Salah satu cara menentukan variabel X mana yang berhubungan dengan variabel X lainnya adalah dengan meregres setia Xi terhadap variabel X sisanya dan menghitung nilai R2. Hubungan antara F dan R2 dapat dituliskan dalam rumus sebagai berikut :
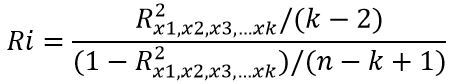
Variabel mengikuti distribusi F dengan derajad bebas (df) k – 2 dan n – k + 1, n adalah ukuran sampel, k jumlah variabel independen termasuk intersep, dan

adalah koefisien determinasi dalam regresi Xi berkorelasi tinggi dengan variabel X’s lainnya. Tanpa menguji semua nilai R2 auxilary, kita dapat menggunakan kriteria kasar Klien’s of Tumbu yang menyatakan bahwa multikolinearitas menjadi bermasalah jika R2 yang diperoleh dari auxilary regression lebih tinggi daripada R2 keseluruhan yang diperoleh dari meregres semua variabel X’s terhadap Y.

· Eigenvalues dan condition index. Pertama kita menghitung terlebih dahulu nilai eigenvalues, dari nilai eigenvalue ini dapat diperoleh condition number k seperti di bawah ini
Jika nilai k antara 100 dan 1000, maka terdapat multikolinearitas moderat sampai kuat. Jika k lebih besar dari 1000 terdapat multikolinearitas sangat kuat. Cara lain dengan melihat nilai CI antara 10 dan 30 menunjukkan adanya multikolinearitas moderat sampai kuat dan CI di atas 30 terdapat multikolineartias sangat kuat.
· Tolerance dan Variance Inflation Factor (VIF). Multikolinearitas dapat juga dilihat dari (1) nilai tolerance dan lawannya (2) variance inflation factor (VIF). Kedua ukuran ini menunjukkan setipa variabel independen manakah yang dijelaskan oleh variabel independen lainnya. Dalam pengertian sederhana setiap variabel independen menjadi variabel dependen dan diregres terhadap variabel independen lainnya. Tolerance mengukur variabilitas variabel independen terpilih yang tidak dijelaskan oleh variabel independen lainnya. Jadi tolerance yang rendah sama dengan nilai VIF yang tinggi (karena VIF = 1/tolerance). Nilai Cut off yang umum dipakai untuk menunjukkan adanya multikolinearitas adalah tolerance < 0,1 atau sama dengan VIF > 10. Setiap peneliti harus menentukan tingkat kolinearitas yang masih dapat ditolerir. Sebagai misal tolerance = 0,1 sama dengan tingkat kolinearitas 0,9. Walaupun multikolinearitas dapat dideteksi dengan nilai tolerance dan VIF, tetapi kita masih tetap tidak mengetahui variabel-variabel independen mana sajakah yang saling berkorelasi.
4. No Autocorrelation
Autokorelasi adalah terjadinya korelasi antara satu variabel error dengan variabel error yang lain. Autokorelasi seringkali terjadi pada data time series dan dapat juga terjadi pada data cross section tetapi jarang (Widarjono, 2007).
Adapun dampak dari adanya autokorelasi dalam model regresi adalah sama dengan dampak dari heteroskedastisitas yang telah diuraikan di atas, yaitu walaupun estimator OLS masih linier dan tidak bias, tetapi tidak lagi mempunyai variansi yang minimum dan menyebabkan perhitungan standard error metode OLS tidak bisa dipercaya kebenarannya. Selain itu interval estimasi maupun pengujian hipotesis yang didasarkan pada distribusi t maupun F tidak bisa lagi dipercaya untuk evaluasi hasil regresi. Akibat dari dampak adanya autokorelasi dalam model regresi menyebabkan estimator OLS tidak menghasilkan estimator yang BLUE dan hanya menghasilkan estimator OLS yang LUE (Widarjono, 2007).
Selanjutnya untuk mendeteksi adanya autokorelasi dalam model regresi linier berganda dapat digunakan metode Durbin-Watson. Durbin-Watson telah berhasil mengembangkan suatu metode yang digunakan untuk mendeteksi adanya masalah autokorelasi dalam model regresi linier berganda menggunakan pengujian hipotesis dengan statistik uji yang cukup populer seperti pada persamaan berikut.

Kemudian Durbin-Watson berhasil menurunkan nilai kritis batas bawah (dL) dan batas atas (dU) sehingga jika nilai d hitung dari persamaan di atas terletak di luar nilai kritis ini, maka ada atau tidaknya autokorelasi baik positif atau negatif dapat diketahui. Deteksi autokorelasi pada model regresi linier berganda dengan metode Durbin-Watson adalah seperti pada berikut.
Tabel Uji Statistik Durbin-Watson

Salah satu keuntungan dari uji Durbin-Watson yang didasarkan pada error adalah bahwa setiap program komputer untuk regresi selalu memberi informasi statistik d. Adapun prosedur dari uji Durbin-Watson adalah (Widarjono, 2007) :
· Melakukan regresi metode OLS dan kemudian mendapatkan nilai errornya.
· Menghitung nilai d.
· Dengan jumlah observasi (n) dan jumlah variabel bebas tertentu tidak termasuk konstanta (p-1), kita cari nilai kritis dan di statistik Durbin-Watson.
· Keputusan ada atau tidaknya autokorelasi dalam model regresi didasarkan pada Tabel di atas.
Selain Kriteria uji seperti pada Tabel di atas, dapat juga digunakan kriteria lain untuk mendeteksi adanya autokorelasi dalam model regresi linier berganda adalah sebagai berikut (Santoso, 2000):
· Jika nilai d < −2, maka ada autokorelasi positif.
· Jika −2 ≤ d ≤ 2, maka tidak ada autokorelasi.
· Jika nilai d > 2, maka ada autokorelasi negatif.
0 Response to "Analisis Regresi Linear Sederhana"
Posting Komentar